SRE Terminology

Introduction
Site Reliability Engineering (SRE) is an approach to software engineering that emphasizes reliability, scalability, and maintainability. It is a discipline that combines software engineering and operations to build and run large-scale, distributed systems. As with any field, SRE has its own set of terminology, acronyms, and jargon that can be confusing for newcomers. In this blog post, we will discuss some of the most common terms and concepts used in SRE.
What is SRE?
Site Reliability Engineering (SRE) is a discipline that applies software engineering to operations. Its aim is to build and maintain highly reliable and scalable applications. Although it was created at Google, SRE is now widely adopted throughout the technology industry.
Part of the SRE creed is that “every failure is an opportunity for learning.” Therefore, engineers must find the contributing factors to a problem and make system-level adjustments to ensure that the issue doesn’t resurface.
What Problems Does SRE Solve?
SRE tries to reduce system outages and downtime by identifying and addressing issues quickly. By investigating incidents and analyzing them, SRE teams help the DevOps team build and modify systems to be highly available and resilient by design.
SRE also helps ensure that software in production meets all user needs, whether internal or external. The SRE team monitors usage patterns and capacity to ensure that the IT environment can handle expected traffic, avoiding overloading and service disruption.
SRE teams collaborate closely with DevOps teams to confirm that issues are truly resolved. There is a constant feedback loop between SRE and DevOps to guarantee that flaws are fixed at the source and not just temporarily patched.
The Benefits of SRE
In addition to its primary objective of improving system reliability, SRE teams help design operable systems that are less likely to fail or experience unplanned downtime. SRE promotes:
- Faster incident resolution: A data-driven approach to issue identification enables SRE teams to address incidents quickly and reduce the time to detect and resolve them.
- Efficient resource utilization: SRE teams optimize resource usage to ensure that systems can scale efficiently without requiring significant additional resources.
- Improved collaboration: Close collaboration with development teams ensures that software is designed with reliability in mind from the outset.
- Greater automation: SRE teams use automation to reduce the risk of human error and increase efficiency, freeing up time for more strategic work for both DevOps and SRE teams.
Glossary Summary
As the field of SRE continues to grow, it is important for practitioners to have a common vocabulary and understanding of the key terms and concepts that are used in the discipline. This glossary provides an overview of some of the most important SRE terms and definitions, including availability, error budget, and incident response. By familiarizing themselves with these concepts, SRE teams can better understand the challenges and opportunities that arise in their work, and develop more effective strategies for improving the reliability and availability of their systems. As SRE continues to evolve, it is likely that new terms and concepts will emerge, and it will be important for practitioners to stay up-to-date with the latest developments in the field.
glossary
SLASLOSLIRTORPOMTTRMTTFMTBFWAFshared responsibility modelCI/CDContinuous DeliveryContinuous DeploymentAgileScrumKanbanIaCPerformance testingLoad testingStress testingFault injection testingChaos EngineeringDisaster/recovery testingMultiregionzone redundancyAvailability zoneEndpoint monitoringThrottlingcircuit breaker patternIdempotent taskAvoid affinityVertical scaling (up/down)Horizontal scaling (out/in)autoscalingApplication GatewayLoad Balancerhot standbycold standbyActive-activePush modelPull modelDSCPipelineArtifactsBlue-Green DeploymentCanary DeploymentsRing-based deploymentsA/B TestingKey VaultObservabilityMonitoringerror budget
Explained
SLA, SLO, and SLI
A Service Level Agreement (SLA) is a contract between a service provider and its customers that defines the level of service that will be provided. SLAs typically specify the availability, uptime, response time, and other key metrics that the service provider must meet.
A Service Level Objective (SLO) is a target that the service provider sets for itself, based on the SLA. SLOs are used to measure the performance of the service provider and to ensure that it meets its commitments to customers. The SLO should be set at a level that is achievable and meaningful to the customer.
A Service Level Indicator (SLI) is a measurement of the performance of a service. SLIs are used to track the performance of the service and to identify areas where improvements can be made. The SLI should be a metric that is meaningful to the customer and that can be tracked over time.
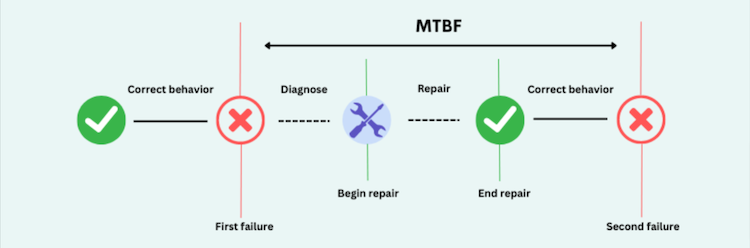
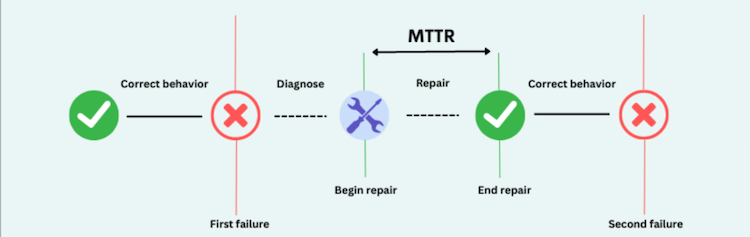
Error Budget and Toil
An Error Budget is the amount of time that a service can be unavailable or perform poorly, without violating the SLO. The error budget is a key concept in SRE because it provides a way to balance reliability and innovation. If the error budget is exhausted, the service provider must focus on improving reliability rather than adding new features.
Toil refers to repetitive, manual work that is necessary to keep a service running. Toil is a problem in SRE because it takes time away from more valuable work, such as improving the reliability of the service. SRE teams should strive to minimize toil by automating repetitive tasks and by eliminating unnecessary work.
Incident Management and Postmortem
Incident Management is the process of responding to incidents and outages. The goal of incident management is to minimize the impact of the incident on customers and to restore service as quickly as possible. Incident management typically involves identifying the cause of the incident, mitigating the impact, and communicating with customers.
Postmortem is the process of analyzing incidents and outages to identify their root cause and to prevent them from happening again. Postmortems are a key part of SRE because they provide a way to learn from incidents and to improve the reliability of the service. Postmortems should be conducted in a blameless manner and should focus on identifying ways to improve the system.