RocksDB
Common KV Stores
Common KV stores include:
- Memory-based Redis
- Single-machine disk-based LevelDB, RocksDB
- Distributed (over TB level) Cassandra, Hbase
RocksDB
Installation
RocksDB is written in C++, and because the official binary library for the corresponding platform is not provided, different platform-compiled libraries are not interchangeable, so you need to compile and use them on the corresponding platform. If you use RocksDBJava, this problem is much better, but the Java API is always behind the C++ version.
Before installing RocksDB, you need to understand what an embedded kv-store is. For non-embedded kv-stores, such as using Redis, you need to install Redis-server first, and then read and write data through Redis-client. For embedded kv-stores, there is no specific server, and data storage is directly operated through code, that is, you only need to introduce the relevant dependencies of RocksDB into your project (add dependencies in Java to maven) to start developing.
C++
RocksDB Install: https://github.com/facebook/rocksdb/blob/master/INSTALL.md
# If ./configure reports an error like configure: error: C++ compiler cannot create executables, this means that the C++ component is missing
$ yum install -y gcc gcc-c++ gcc-g77
# Install gflags
$ git clone <https://github.com/gflags/gflags.git>
$ cd gflags
$ git checkout v2.0
$ ./configure && make && sudo make install
# Install snappy:
$ sudo yum install -y snappy snappy-devel
# Install zlib:
$ sudo yum install -y zlib zlib-devel
# Install bzip2:
$ sudo yum install -y bzip2 bzip2-devel
# Install lz4:
$ sudo yum install -y lz4-devel
# Install ASAN (optional for debugging):
$ sudo yum install -y libasan
# Install zstandard:
$ wget <https://github.com/facebook/zstd/archive/v1.1.3.tar.gz>
$ mv v1.1.3.tar.gz zstd-1.1.3.tar.gz
$ tar zxvf zstd-1.1.3.tar.gz
$ cd zstd-1.1.3
$ make && sudo make install
# Install rocksdb
$ git clone <https://github.com/facebook/rocksdb.git>
$ cd rocksdb
# Compile static library, release mode, get librocksdb.a
$ make static_lib
# Compile dynamic library, release mode, get librocksdb.so
$ make shared_lib
$ cp librocksdb.a /usr/lib
$ cp -r include/ /usr/include
$ cp librocksdb.so /usr/lib
$ sudo ldconfig
Java
RocksJava Basics: https://github.com/facebook/rocksdb/wiki/RocksJava-Basics
<dependency>
<groupId>org.rocksdb</groupId>
<artifactId>rocksdbjni</artifactId>
<version>5.17.2</version>
</dependency>
Management Tool
Use ldb and sst_dump to manage RocksDB, after installing the above C++ dependencies
# Linux
$ cd rocksdb
$ make ldb sst_dump
$ cp ldb /usr/local/bin/
$ cp sst_dump /usr/local/bin/
# OSX
$ brew install rocksdb
# Corresponding commands are
$ rocksdb_ldb
$ rocksdb_sst_dump
For the usage of ldb and sst_dump, please refer to the official document https://github.com/facebook/rocksdb/wiki/Administration-and-Data-Access-Tool
examples
View all keys of all databases
#!/bin/bash
export DATA_PATH=/hadoop/rockfs/data
export DB_INSTANCES=$(ls /hadoop/rockfs/data)
for i in $DB_INSTANCES; do
ldb --db=$DATA_PATH/$i/ scan 2>/dev/null;
done
View SST file properties
# Note that --file needs to specify the absolute path
$ sst_dump --file=$DATA_PATH/test --show_properties
from [] to []
Process /hadoop/rockfs/data/0006.sst
Sst file format: block-based
Table Properties:
------------------------------
# data blocks: 26541
# entries: 2283572
raw key size: 264639191
raw average key size: 115.888262
raw value size: 26378342
raw average value size: 11.551351
data block size: 67110160
index block size: 3620969
filter block size: 0
(estimated) table size: 70731129
filter policy name: N/A
# deleted keys: 571272
# If sst_dump: error while loading shared libraries: libgflags.so.2: cannot open shared object file: No such file or directory
$ find / -name libgflags.so.2
/root/gflags/.libs/libgflags.so.2
/usr/local/lib/libgflags.so.2
# It can be seen that the dependency has been downloaded, but it has not been found. Specify the dependency library manually
$ vim /etc/ld.so.conf.d/usr-libs.conf
/usr/local/lib
$ sudo ldconfig
Upgrade gcc to 8.1
Download gmp-5.1.1.tar.bz2, mpfr-3.1.5.tar.bz2, mpc-1.1.0.tar.gz, gcc-8.0.1.tar.gz from http://mirror.hust.edu.cn/gnu
yum install -y m4
tar -xvf gmp-5.1.1.tar.bz2
cd gmp-5.1.1
./configure --prefix=/usr/local/gmp-5.1.1 && make
make install
tar -xvf mpfr-3.1.5.tar.bz2
cd mpfr-3.1.5
./configure --prefix=/usr/local/mpfr-3.1.5 --with-gmp=/usr/local/gmp-5.1.1 && make
make install
tar -zxvf mpc-1.1.0.tar.gz
cd mpc-1.1.0
./configure --prefix=/usr/local/mpc-1.1.0 --with-gmp=/usr/local/gmp-5.1.1 --with-mpfr=/usr/local/mpfr-3.1.5 && make
make install
tar -zxvf gcc-8.0.1.tar.gz
export LD_LIBRARY_PATH=/usr/local/mpc-1.1.0/lib:/usr/local/gmp-5.1.1/lib:/usr/local/mpfr-3.1.5/lib:$LD_LIBRARY_PATH
cd gcc-8.0.1
./configure --prefix=/usr/local/gcc-8.0.1 --enable-threads=posix --disable-checking --disable-multilib --enable-languages=c,c++ --with-gmp=/usr/local/gmp-5.1.1 --with-mpfr=/usr/local/mpfr-3.1.5 --with-mpc=/usr/local/mpc-1.1.0 && make
make install
LSM-Tree(Log-Structured-Merge Tree)
Background
LSM provides better write throughput than traditional B+ trees or ISAM by eliminating random disk I/O. The fundamental problem is that whether it is HDD or SSD, random read and write are slower than sequential read and write, especially for mechanical hard disks. However, if we write to the disk sequentially, the speed is comparable to that of writing to memory: because it reduces the seek time and rotation time. Moreover, in the case of sequential writing, the data can be put into the buffer first, waiting for the number to reach one page of the disk before being written to further reduce the number of disk IOs.
For example, for log data, they have a strict time order, so they can be written sequentially. When you want to search for data, you need to scan all the data, similar to grep, so the search speed is relatively slow O(n).
For cases where there is a lot of data, the general way to improve reading performance is
- Binary search: Sort file data by
keyand use binary search to complete the search for a specifickey,O(logN). - Hash: Divide the data into different
bucketsusing a hash, and when querying some data, get thebucketwhere the data is located through the hash function, and then traverse a small amount of data in thebucket. - B+ tree: Using
B+trees orISAMmethods can reduce the read of external files - External files: Save the data as logs and create a
hashor search tree to map the corresponding file.
The above methods effectively improve the reading performance by arranging and storing data according to fixed data structures, but also increase a lot of random IO, losing good writing performance, especially when the amount of data is large. For example, when updating the structure of Hash and B+ Tree, part of the data needs to be moved, resulting in random IO.
So how to ensure that the data is sorted in a certain order and then written to the disk in sequence, and support fast data retrieval? It sounds contradictory, but LSM does this.
LSM principle
LSM uses a method different from the above four methods, which maintains the log file write performance and the small read operation performance loss. Essentially, it sequences all operations to avoid random disk reads and writes. How to achieve it?
The basic principle of LSM is to save the addition and modification of data to a number of similar ordered files sstable. Each file contains a certain number of changes in a short period of time. Because the files are ordered, subsequent queries will also be very fast. The file is immutable, and it will never be updated. New updates will only be written to new files. The read operation checks very few files. The background merges these files periodically to reduce the number of files.
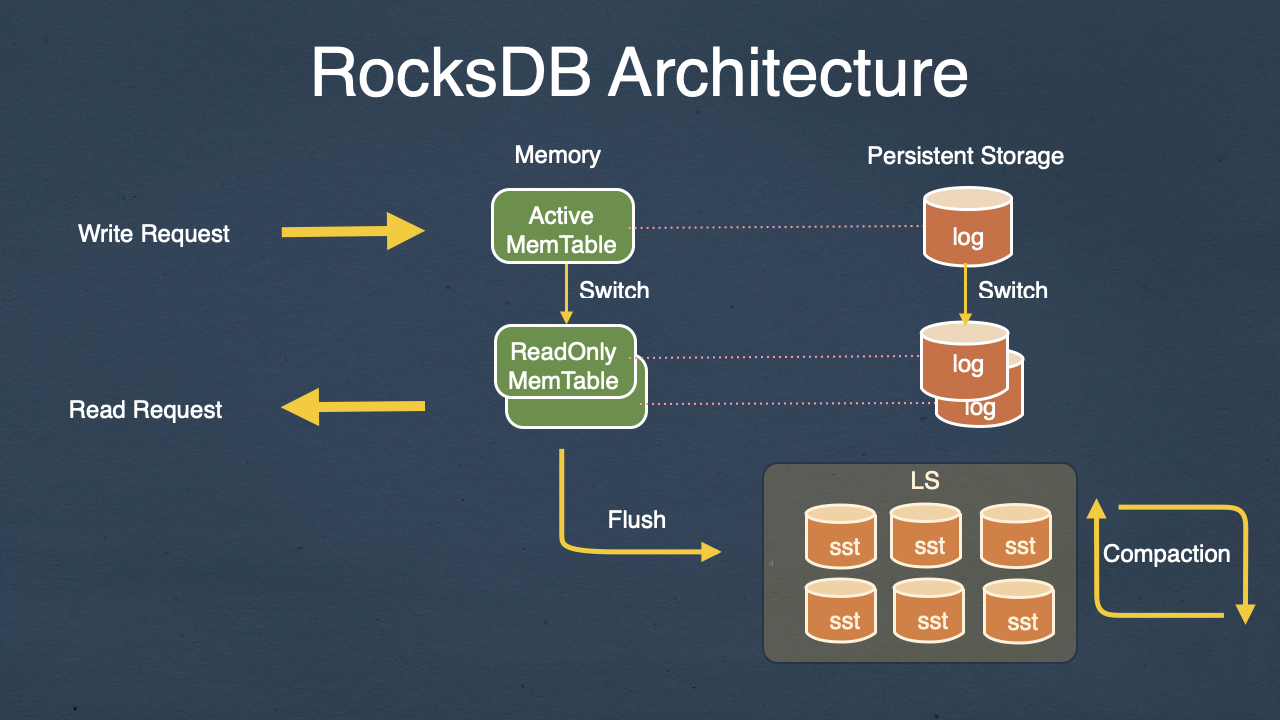
Write principle
When there are new updates, they are first written to the memory cache, that is, memtable. The memtable uses tree structure to keep the key ordered. To ensure that the data is not lost, most implementations write WAL to the disk before the operation is written to memory. When the memtable data reaches a certain size, it will be flushed to the disk to generate an sstfile. In the flush process, the system only performs sequential disk reads and writes. The file is immutable, and the modification of the data is done by writing new files to cover the data in the old files.
Reading Principles
When a read operation comes, the system first checks memtables. If the key is not found, it will sequentially check the sst files in reverse order (newer sst data is prioritized over older sst data) until the key is found or all sst files have been traversed. The search for a single sst file is O(logN), but if there are many sst files, in the worst case, each sst file needs to be checked, so the overall time complexity is O(k*logN), where k is the number of sst files.
Therefore, the read operation of LSM is slower than other locally updated structures, and there are some tricks to improve performance.
- The most basic method is page caching, such as the
TableCacheinLevelDB, which cachessstablesin memory according toLRUto reduce the cost of binary search. - Create an index for each file using
Block Index. - Even if each file has an index, as the number of files increases, read operations will still be slow. Moreover, each read operation still needs to access a large number of files. Is there a way to quickly tell us whether the data we want is in the current
sstfilewithout accessing a large number of index files? The answer is to useBloom Filter. If the Bloom filter tells you that thekeyis not in the current set, it will definitely not exist. But if it tells you that it is, it may not exist in reality, and there is a certain probability that thekeyyou want to find is not in the current set. However, this does not affect the efficiency ofBloom Filter, which avoids unnecessary file reads.
All write operations are processed in batches and written only to the sequential block. In addition, the periodic operation of the merge operation will have an impact on IO, and read operations may access a large number of files (scattered reads). This simplifies the algorithm work method, and we exchange the random IO of reading and writing. This compromise is meaningful, and we can optimize read performance through software techniques such as Bloom filters or hardware (large file cache).
Basic Compaction
Summary
LSM is neutral between log and traditional single-file indexes (B+ tree, Hash Index). It provides a mechanism for managing smaller independent index files (sstable). By managing a group of index files instead of a single index file, LSM makes expensive random IO of structures such as B+ trees faster, at the cost of read operations that need to process many index files (sstable) rather than one. In addition, some IOs are consumed by merge operations.
Reference
Terminology
Terminology: https://github.com/facebook/rocksdb/wiki/Terminology
Storage Types
RocksDB has three very important structures: memtable, sstfile, and logfile.
memtable: As the name suggests, it is a data structure in memory.memtableis divided into two types:active memtableandimmutable memtable. When theactive memtableis full, it becomesimmutable memtableand is written tosstfileand successfully saved to disk. After that, the data in memory can be cleared. The format of a default sstfile (https://github.com/facebook/rocksdb/wiki/Rocksdb-BlockBasedTable-Format).sstfile:sorted string table, which is an ordered string of datakey.sstis layered, and each layer is larger than the previous one. The data in the upper layer and the lower layer are newer than the data in the lower layer. When thekeyin the upper layer is hit, thekeyin the lower layer is not queried, and only the old version of thekeyis deleted duringcompaction.logfile: When new data is written, it is inserted intomemtable. By choosing to enableWAL, the data operation is written tologfilebefore it is written to protect against the loss of data written to memory.logfileis a sequential log file written to disk.
Compaction
Compaction mainly includes two types: the process of dumping imutable from memory to disk sst is called flush or minor compaction. The process of dumping sst files on disk from lower levels to higher levels is called compaction or major compaction. There are separate threads for minor compaction and major compaction, which can be controlled by parameters rocksdb_max_background_flushes and rocksdb_max_background_compactions. Through minor compaction, data in memory is continuously written to disk to ensure that there is enough memory to cope with new writes. Through major compaction, the duplicate and useless data between multiple layers of SST files can be quickly reduced, thereby reducing the disk space occupied by SST files. For reading, since the number of sst files that need to be accessed is reduced, performance is also improved. Since the compaction process is continuously operating in the background, the amount of content compaction in a unit of time is not large, which will not affect the overall performance. Of course, this can be adjusted according to the actual situation by adjusting the parameters. The overall architecture of compaction can be seen in Figure 1. Understanding the basic concepts of compaction, the following will introduce the process of compaction in detail, mainly including two parts: flush (minor compaction) and compaction (major compaction), and the corresponding entry functions are BackgroundFlush and BackgroundCompaction.
RocksDB Tuning
Amplification Factors
In fact, a large part of the work of tuning a database system is to balance between the three amplification factors: write amplification, read amplification, and space amplification.
- Write Amplification: On average, one byte is written, and
nbytes are actually written during the data’s life cycle in the engine (for example, thecompactionoperation will write the data again after merging and compressing), and its write amplification rate isn. That is, if the write speed is10mb/sin the business side, and the data write speed observed in the engine or operating system level is30mb/s, then the write amplification rate of the system is3. A high write amplification rate will limit the actual throughput of the system. Moreover, for SSDs, the larger the write amplification, the shorter the life of the SSD. - Read Amplification: For a small read request, the system needs to read
npages to complete the query. Its read amplification rate isn. The logical read operation may hit the internalcacheof the engine or the file systemcache, and if it does not hit thecache, it will carry out actual disk IO. The cost of reading operations that hit thecacheis very low, but it also consumes CPU. - Space Amplification: It means that on average, storing one byte of data occupies
nbytes of disk space in the storage engine. Its space amplification isn. For example, if you write10mbof data and it actually occupies100mbon the disk, the space amplification rate is10. Space amplification and write amplification are often mutually exclusive in tuning. The larger the space amplification, the less frequent data needs to becompaction, and the lower the write amplification will be; if the space amplification rate is set small, the data will need to becompactionfrequently to release storage space, which will increase the write amplification.
Statistics
Statistics is a function that RocksDB uses to statistically analyze system performance and throughput information. Enabling it can provide performance observation data more directly, quickly detect system bottlenecks or system operating status, and increase 5%~10% additional overhead due to the large number of buried points updated by various operations in the engine for statistics, but it is worth it.
** Compaction Stats **
Level Files Size(MB) Score Read(GB) Rn(GB) Rnp1(GB) Write(GB) Wnew(GB) Moved(GB) W-Amp Rd(MB/s) Wr(MB/s) Comp(sec) Comp(cnt) Avg(sec) Stall(sec) Stall(cnt) Avg(ms) KeyIn KeyDrop
------------------------------------------------------------
L0 2/0 15 0.5 0.0 0.0 0.0 32.8 32.8 0.0 0.0 0.0 23.0 1457 4346 0.335 0.00 0 0.00 0 0
L1 22/0 125 1.0 163.7 32.8 130.9 165.5 34.6 0.0 5.1 25.6 25.9 6549 1086 6.031 0.00 0 0.00 1287667342 0
L2 227/0 1276 1.0 262.7 34.4 228.4 262.7 34.3 0.1 7.6 26.0 26.0 10344 4137 2.500 0.00 0 0.00 1023585700 0
L3 1634/0 12794 1.0 259.7 31.7 228.1 254.1 26.1 1.5 8.0 20.8 20.4 12787 3758 3.403 0.00 0 0.00 1128138363 0
L4 1819/0 15132 0.1 3.9 2.0 2.0 3.6 1.6 13.1 1.8 20.1 18.4 201
Source
https://arch-long.cn/articles/kv%20store/RocksDB.htmlhttps://github.com/facebook/rocksdb/wiki/RocksDB-Overview
Some of the content is generated by AI, please be cautious in identifying it.