Hadoop Secondary Namenode
Introduction
The Secondary Namenode is a poorly named component in Hadoop. Its name suggests that it serves as a backup for the Namenode, but in reality, it does not. Many beginners in Hadoop get confused about the role of the Secondary Namenode in HDFS. In this blog post, we will explain the true role of the Secondary Namenode.
You may assume from its name that it has something to do with the Namenode, and you would be correct. However, before we dive into the Secondary Namenode, let’s first examine what exactly the Namenode does.
Namenode
The Namenode holds metadata for the HDFS, like namespace information and block information. When in use, all this information is stored in main memory. However, this information is also stored on disk for persistent storage.
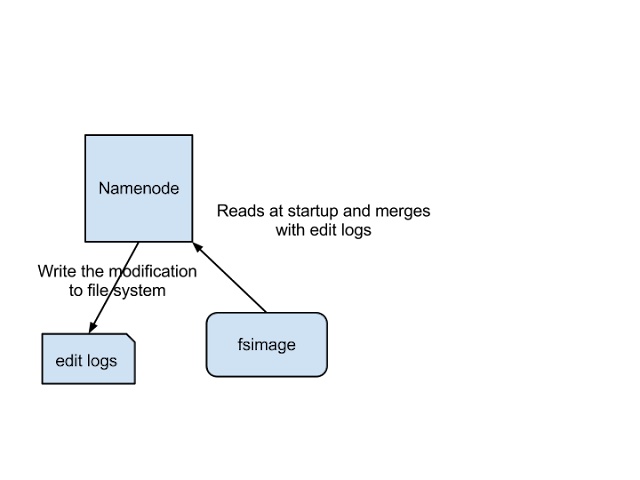
The above image illustrates how the Name Node stores information on disk.
There are two different files:
fsimage- This is a snapshot of the filesystem when the namenode started.Edit logs- This is the sequence of changes made to the filesystem after the namenode started.
Only during a restart of the namenode are the edit logs applied to the fsimage to obtain the latest snapshot of the file system. However, namenode restarts are rare in production clusters, which means that the edit logs can grow very large for clusters where the namenode runs for a long period of time. This can result in the following issues:
- The edit log becomes very large, making it challenging to manage.
- Namenode restarts take a long time because many changes must be merged.
- In the event of a crash, a significant amount of metadata will be lost because the
fsimageis very old.
To address these issues, we need a mechanism that helps us reduce the size of the edit log, making it manageable, and ensures that the fsimage is up to date, reducing the load on the namenode. This mechanism is similar to Windows Restore Point, which allows us to take a snapshot of the OS so that if something goes wrong, we can revert to the last restore point.
Now that we understand the NameNode’s functionality and the challenges of keeping the metadata up to date, what does this have to do with the Secondary Namenode?
Secondary Namenode
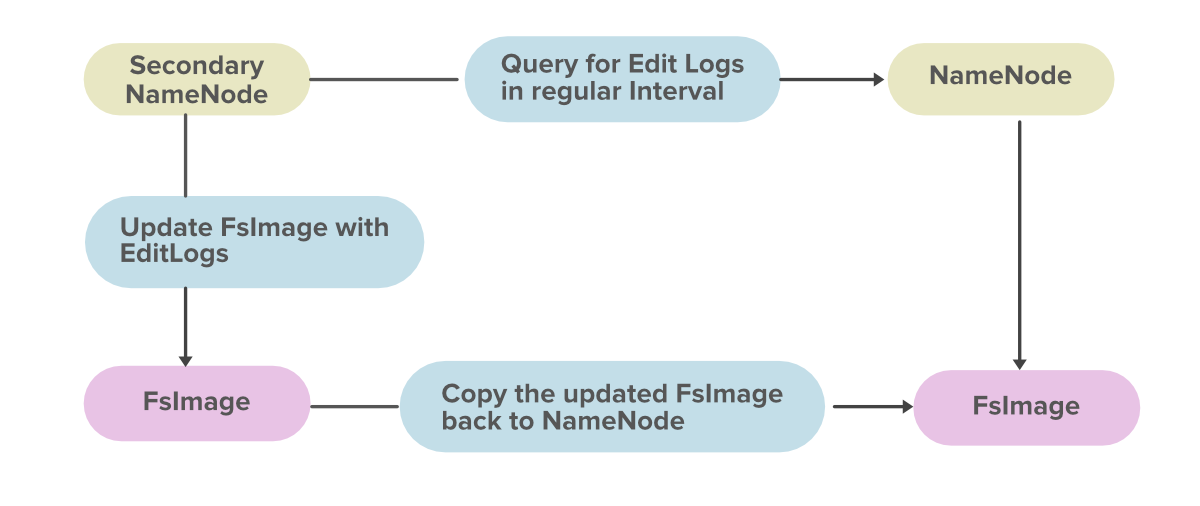
The Secondary Namenode addresses the aforementioned issues by taking on the responsibility of merging editlogs with fsimage from the primary namenode.
The figure above illustrates the functioning of the Secondary Namenode:
- It periodically receives edit logs from the Namenode and applies them to the fsimage.
- Once it has a new fsimage, it copies it back to the Namenode.
- The Namenode will use this fsimage for the next restart, which reduces the startup time.
The Secondary Namenode’s main purpose is to create a checkpoint in HDFS. It is a helper node for the Namenode and is also referred to as a checkpoint node within the community.
To clarify, the Secondary Namenode is not a replacement or backup for the Namenode. Its sole function is to provide a checkpoint in the filesystem, which improves the Namenode’s performance. Thus, it is more appropriate to refer to it as a checkpoint node.
Reference
https://blog.madhukaraphatak.com/secondary-namenode---what-it-really-do/