Install Hadoop 2.6.3 cluster on CentOS 6.7
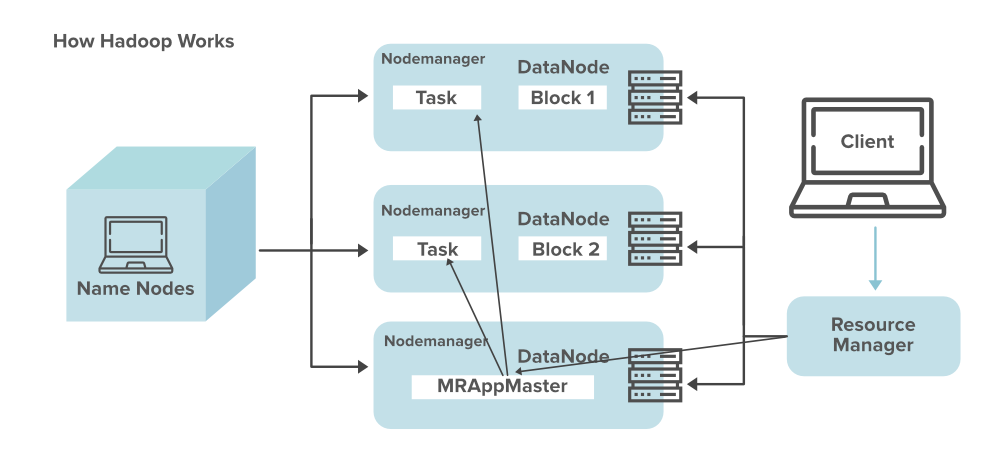
Install Hadoop 2.6.3 fully distributed environment on CentOS 6.7 x64 and test it on DigitalOcean.
- Tip: SSH passwordless login is not required for intranet deployment.
- Tip: The memory of a single NameNode/DataNode should be greater than 1G. It may not start successfully on a machine with 512MB memory.
This article assumes:
Domain name (hostname) of the master node (NameNode): m.fredlab.org
Domain name (hostname) of the child node (DataNode): s1.fredlab.org
s2.fredlab.org
s3.fredlab.org
I. Configure SSH passwordless login
(1) Generate public and private keys on the master machine: id_rsa and id_rsa.pub
ssh-keygen
(2) Upload them to the .ssh/ directory on each node machine.
.ssh/----
|--
|--id_rsa
|--id_rsa.pub
|--authorized_keys
(3) Change the private key permissions to 0600.
chmod 0600 id_rsa
(4) Copy the public key to authorized_keys.
cat id_rsa.pub >> authorized_keys
(5) Configure SSH passwordless login (optional).
Change the following two lines in /etc/ssh/ssh_config:
StrictHostKeyChecking no
GSSAPIAuthentication no
Restart the ssh service.
service sshd restart
II. Configure domain name (hostname)
(1) Change the hostname.
vim /etc/sysconfig/network
Change [HOSTNAME=s1.fredlab.org] (hostname), and similarly for other nodes.
(2) Add the hostname and corresponding IP address to /etc/hosts, in a format like:
104.236.142.235 m.fredlab.org
104.236.143.22 s1.fredlab.org
104.236.143.54 s2.fredlab.org
107.170.224.199 s3.fredlab.org
III. Install Java JDK
(1) Download java jdk rpm package.
http://www.oracle.com/technetwork/java/javase/downloads/index.html
(2) Install.
rpm -ih jdk-8u72-linux-x64.rpm
(3) Check the java path and version.
which java
which javac
java -version
(4) The default JAVA_HOME=/usr.
IV. Install Hadoop 2.6.3
Note: The following operations are performed on the master.
(1) Download Hadoop 2.6.3.
wget <http://www.eu.apache.org/dist/hadoop/common/hadoop-2.6.3/hadoop-2.6.3.tar.gz>
(2) Unzip and install (installation location /usr/local/hadoop2).
tar zxf hadoop-2.6.3.tar.gz
mv hadoop-2.6.3 /usr/local/hadoop2
(3) Add data directory and temporary directory (location is optional, corresponding to the configuration file).
mkdir /usr/local/hadoop2/tmp
mkdir /usr/local/hadoop2/hdfs
(4) Modify the configuration file (located in /usr/local/hadoop2/etc/hadoop/).
Main configuration file: core-site, where m.fredlab.org is the domain name (hostname) of NameNode.
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop2/tmp</value>
<description>temp dir</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://m.fredlab.org:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
HDFS configuration file: hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop2/hdfs/data</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>10</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
Yarn configuration file: yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
MapReduce configuration file: mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Add the java path to [hadoop-env.sh] and [yarn-env.sh].
echo "export JAVA_HOME=/usr" >> hadoop-env.sh
echo "export JAVA_HOME=/usr" >> yarn-env.sh
Add the domain name (hostname) of each node to the slaves file, one per line, like:
s1.fredlab.org
s2.fredlab.org
s3.fredlab.org
V. Copy the configured Hadoop to each slave
Copy the /usr/local/hadoop2 directory to each DataNode machine.
scp -r /usr/local/hadoop2 root@s1.fredlab.org:/usr/local/
VI. Start the Hadoop cluster
(1) Format the file system.
/usr/local/hadoop2/bin/hdfs namenode -format
(2) Start the cluster.
Start hdfs.
/usr/local/hadoop2/sbin/start-dfs.sh
Start yarn.
/usr/local/hadoop2/sbin/start-yarn.sh
(3) Check the file system.
/usr/local/hadoop2/bin/hdfs dfsadmin -report
(4) Observe the cluster running status on the web page.
Cluster running status: http://m.fredlab.org:50070
http://master_ip:50070
Cluster application status: http://m.fredlab.org:8088
http://master_ip:8088
(5) View java processes on each node.
NameNode, run on m.fredlab.org: jps
19042 Jps
17669 NameNode
17910 SecondaryNameNode
18199 ResourceManager
18623 JobHistoryServer
DataNode, run on s1.fredlab.org: jps
17521 DataNode
17673 NodeManager
15628 Jps
View yarn node
yarn node -list