ArgoCD

Introduction
Argo is an open source project that provides container-native workflows for Kubernetes. It allows users to easily create, schedule, and manage complex multi-step and multi-node workflows on Kubernetes.
One of the key features of Argo is its ability to handle dependencies between tasks. This allows users to create complex workflows that are composed of smaller, independent tasks that are connected by dependencies. For example, a workflow may consist of several tasks that need to be executed in a specific order, or a task that needs to be executed only if a previous task succeeded.
Argo also provides a user-friendly web UI that allows users to view the status of their workflows, as well as drill down into the details of individual tasks. This makes it easy to troubleshoot and debug issues that may arise during the execution of a workflow.
Another key feature of Argo is its support for parallelism. This allows users to divide their workflow into smaller, independent tasks that can be executed simultaneously, thereby reducing the overall execution time of the workflow.
In addition to its core features, Argo also provides a number of additional features such as support for templating, resource management, and auto-retries. These features make it easy for users to create and manage complex workflows with minimal effort.
Overall, Argo is a powerful tool for managing container-native workflows on Kubernetes. Its support for dependencies, parallelism, and a user-friendly web UI make it a valuable tool for teams that are looking to automate and streamline their workflow processes.
Using Argo CD to implement GitOps for Kubernetes appears simple. However, like any system, the ability to scale GitOps practices is highly dependent on the architecture you choose. This blog post will explore the three most common architectures when implementing Argo CD: single instance, per cluster instances, and a compromise between the two. I will break down the benefits and drawbacks of each one to help you decide what is appropriate for your situation.
Advantages
- Single view for deployment activity across all clusters.
- Single control plane, simplifying the installation and maintenance.
- Single server for easy API/CLI integration.
Disadvantages
- Scaling requires tuning of the individual components.
- Single point of failure for deployments.
- Admin credentials for all clusters in one place.
- Requires a separate “management” cluster.
- Significant network traffic between Argo CD and clusters.
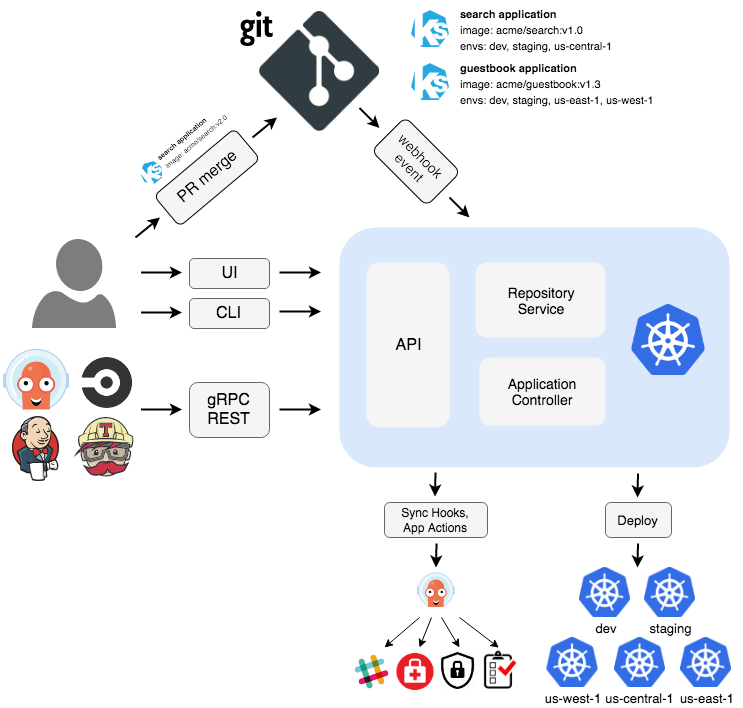
The single control plane approach has one instance of Argo CD managing all clusters. This is a popular approach as it allows users to have a single view of their applications, providing a great developer experience.
In this architecture, there’s only one server URL. This simplifies logging into the argocd CLI and setting up API integrations. It also simplifies the operator experience with just one location for managing the configuration (e.g., repo credentials, users, API keys, CRDs, and RBAC policies).
If your organization is the type to delegate access based on the environment and you are concerned about having all of your applications under one instance, don’t worry, you create the same boundaries using RBAC policies and AppProjects. The project defines what can be deployed where and the RBAC policy will define who can access the project.
However, there are downsides to this architecture. With a single control plane, you have a single point of failure. Your production deployments could be affected by the actions of other environments. Suppose the staging cluster became unresponsive, causing timeouts on the kube-apiserver. This could lead to a high load on the application controller, affecting Argo CD performance for production Applications.
This architecture also requires you to stand up and maintain a dedicated management cluster that will host the Argo CD control plane and have direct access to all your other clusters. Depending on the location of the management cluster, this could involve publicly exposing them, which may raise security concerns.
The admin credentials (i.e., the kubeconfig) for all clusters are stored centrally on this single Argo CD instance (as secrets in the cluster). If a threat actor manages to compromise the management cluster or Argo CD instance, this will grant them widespread access.
It’s also worth mentioning that the application controller must perform Kubernetes watches to gather data from each cluster. You may incur significant costs due to network traffic if the management cluster is in a different region than the other clusters.
Running a single instance means only one controller handles all of this load. Scaling will require tuning the individual Argo CD components (i.e., repo-server, application controller, api-server) as the number of clusters, applications, and repositories increases. Managing Application controller shards is an unpleasant experience that requires manually matching shard size to clusters.
The separation of concern - Instance Per Cluster
Diagram of an Argo CD instance per cluster.
Advantages
- Distributes load per cluster.
- No direct external access is required.
- Eliminates the Argo CD traffic leaving the cluster.
- An outage in one cluster won’t affect other clusters.
- Credentials are scoped per cluster.
Disadvantages
- Requires maintaining multiple instances and duplicating configuration.
- At a particular scale, each instance could still require tuning.
- API/CLI integrations need to specify which instance.
Another typical architecture is to deploy Argo CD to each cluster. It’s most common in organizations where each environment has one Kubernetes cluster. Effectively, you end up with an Argo CD instance for each environment which can simplify security and control.
This method is more secure since Argo CD runs within the cluster, meaning you don’t need to expose the cluster API server to the external control plane. Beyond that, no central instance containing admin credentials for all the clusters. The security domain is limited to a single Argo CD instance. Any other credentials that Argo CD requires (e.g., repo credentials, notifications API keys) can be scoped to the cluster they are in instead of shared among them.
There’s no longer a significant amount of network traffic leaving the cluster to the application controller in the management cluster. This could greatly reduce cloud costs for network traffic. You may incur additional costs due to the additional compute resources required to run every Argo CD component in each cluster.
Scaling is improved because each Argo CD instance only handles a single cluster, and the load is effectively distributed among the environments. However, when the cluster reaches a certain scale (number of applications and repositories), you may still need to tune the individual Argo CD components.
In the same way that the security domain is limited to a single Argo CD instance, the blast radius for outages is also contained. If one cluster is experiencing a significant load to the point that it could prevent application deployments, it will not go on to affect other clusters.
This architecture negatively affects the developer experience. There’s the additional cognitive load of knowing which control plane to point to when using the Argo CD CLI or web interface. You can minimize this with a solid naming strategy and consistency in the server URLs (i.e., each cluster has its FQDN that matches its name, with Argo CD as a subdomain under that).
It’s a painful experience for operators to manage many Argo CD instances. There is a different location to log in to for each cluster, which requires maintenance of RBAC policies and API keys for each one. For that matter, any configuration of Argo CD will need to be copied for each cluster. Be careful of drift, consistency is important. Lower environments should be as production-like as possible to represent the “real” production deployments.
The compromise - Instance Per Logical Group
Diagram of an Argo CD instance per logical group.
Advantages
- Distributes load per group.
- An outage in one cluster won’t affect other groups.
- Credentials are scoped per group.
- Single view for deployment activity across a group.
- Configuration duplication is reduced.
- Easy to understand location for API/CLI integration.
Disadvantages
- Requires maintaining multiple instances.
- At a certain scale, each instance could still require tuning.
- API/CLI integrations need to specify the right instance.
- Requires a separate “management” cluster.
This final architecture balances the previous two, running one Argo CD instance per logical group of clusters. This grouping could be per team, region, or environment. Whatever makes sense for your situation. You probably already have a way of grouping applications internally; this is a great place to start.
This architecture is beneficial when running multiple clusters per environment. It takes away the pain of maintaining too many instances of Argo CD. The RBAC, AppProject, and other configurations will likely be similar for all of the clusters managed by an instance. So the configuration duplication is reduced compared to running an instance for each cluster.
The groups partition the load, which distributes the burden on the application controller, repo server, and API server. It also allows you to limit the blast radius of what can be impacted by Argo, which is a great approach for security and reliability. The grouping isn’t a perfect solution, though, since depending on the size of the clusters, it may still require tuning the individual Argo CD components.
The developer experience is improved compared to the instance per cluster architecture. Following an understood convention for the grouping will reduce the cognitive burden of knowing where to point their CLI and API Integrations for Argo CD.
Reference
https://argoproj.github.io/argo/https://argo-cd.readthedocs.io/en/stablehttps://akuity.io/blog/argo-cd-architectures-explained/