Hadoop HDFS Data Write Mechanism
Introduction to HDFS
HDFS is the distributed file system in Hadoop that is used for storing huge volumes and a variety of data. HDFS follows a master-slave architecture, in which the NameNode is the master node and the DataNodes are the slave nodes. The files in HDFS are broken down into data blocks. The metadata about the blocks is stored in the NameNode, while the data blocks themselves are stored in the DataNodes.
Writing to HDFS
To write data to HDFS, the client first interacts with the NameNode to obtain permission to write data and the IP addresses of DataNodes where the client can write the data. The client then directly interacts with the DataNodes to write the data. The DataNode creates replicas of the data block to other DataNodes in the pipeline based on the replication factor.
During the write operation, DFSOutputStream in HDFS maintains two queues: a data queue and an ack queue.
1. Client Interaction with HDFS NameNode
- When a client wants to write a file in HDFS, it first interacts with the NameNode.
- The NameNode checks the client’s privileges to write a file. If the client has sufficient privileges and there is no file with the same name, the NameNode creates a record for the new file.
- The NameNode then provides the client with the addresses of all DataNodes where it can write its data. It also provides a security token that the client needs to present to the DataNodes before writing the block.
- If a file with the same name already exists in HDFS, file creation fails, and the client receives an IO Exception.
2. The client interacts with the HDFS DataNode
Upon receiving the list of DataNodes and file write permissions, the client begins writing data directly to the first DataNode in the list. Once the client finishes writing data to the first DataNode, the DataNode creates replicas of the block on other DataNodes as required by the replication factor.
In case the replication factor is 3, at least 3 copies of the blocks are created on different DataNodes. After creating the required replicas, the DataNode sends an acknowledgment to the client.
This process creates a pipeline and replicates data to the desired value in the cluster.
Internals of File Write in Hadoop HDFS
Let’s take a detailed look at the HDFS write operation. The following steps take place when writing a file to the HDFS:
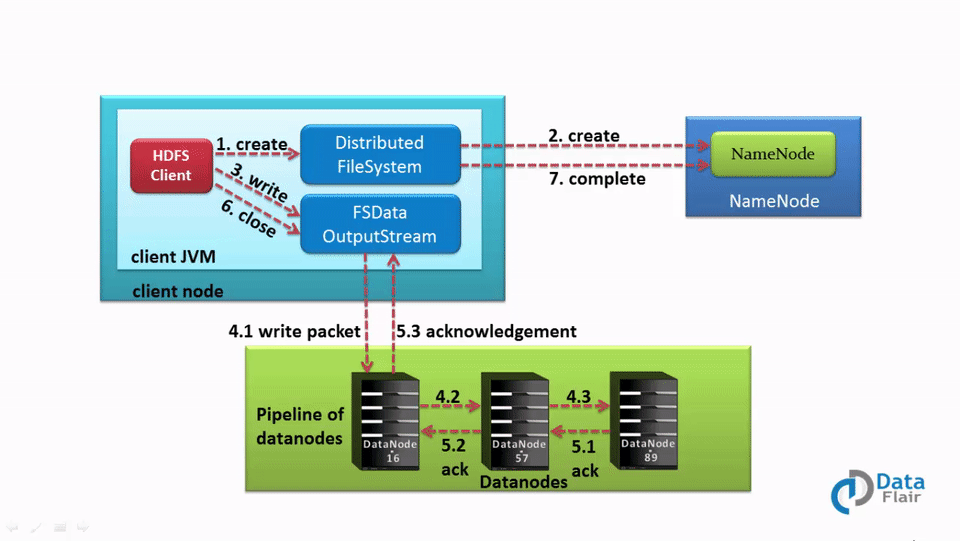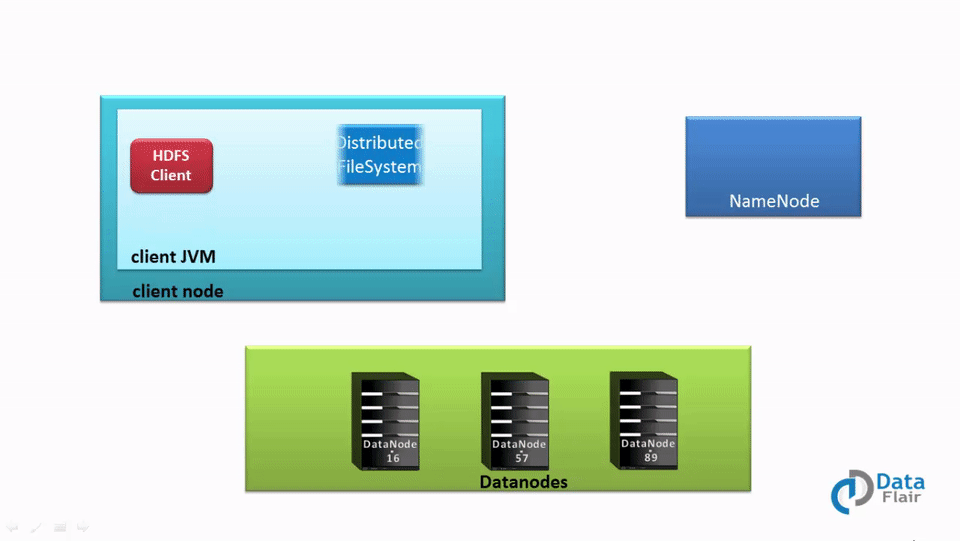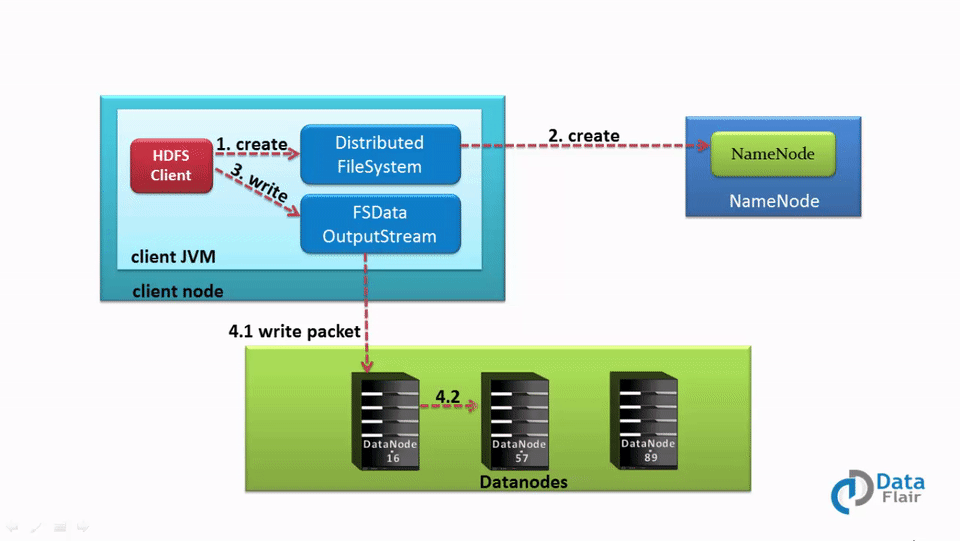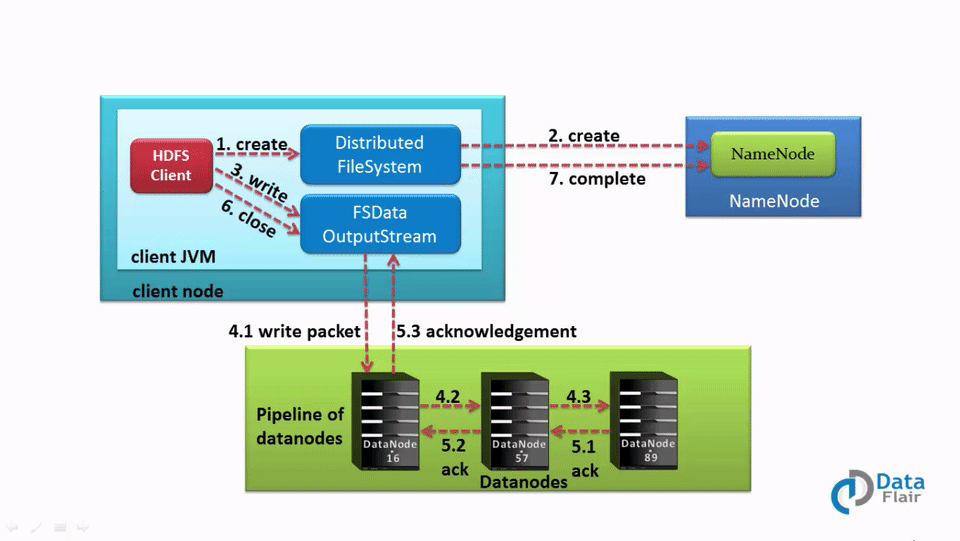
1. The client calls the create() method on DistributedFileSystem to create a file.
2. DistributedFileSystem interacts with the NameNode through an RPC call to create a new file in the filesystem namespace with no blocks associated with it.
3. The NameNode checks for client privileges and ensures that the file does not already exist. If the client has sufficient privileges and there is no file with the same name, the NameNode records the new file. Otherwise, the client receives an I/O exception, and file creation fails. The DistributedFileSystem then returns an FSDataOutputStream for the client to start writing data. FSDataOutputstream, in turn, wraps a DFSOutputStream, which handles communication with the DataNodes and NameNode.
4. As the client starts writing data, the DFSOutputStream splits the data into packets and writes them to an internal queue called the data queue. The DataStreamer, which is responsible for telling the NameNode to allocate new blocks by choosing the list of suitable DataNodes to store the replicas, uses this data queue.
The list of DataNodes forms a pipeline. The number of DataNodes in the pipeline depends on the replication factor.
For example, if the replication factor is 3, there are three nodes in the pipeline.
The DataStreamer streams the packet to the first DataNode in the pipeline, which stores each packet and forwards it to the second node in the pipeline. Similarly, the second DataNode stores the packet and transfers it to the next node in the pipeline (last node).
5. The DFSOutputStream also maintains another queue of packets called the ack queue. Packets in the ack queue are removed only when they receive acknowledgment from all the DataNodes in the pipeline.
6. When the client finishes writing data, they call the close() method on the stream. Before communicating with the NameNode to signal that the file is complete, the client’s close() method pushes the remaining packets to the DataNode pipeline and waits for acknowledgment.
7. As the NameNode already knows about the blocks that make up the file, the NameNode only waits for the blocks to be minimally replicated before returning successfully.
If you are finding it difficult to understand, you can watch this video to understand the HDFS file write operation easily.
What happens if a DataNode fails while writing a file in the HDFS?
If a DataNode fails while writing data, the following actions take place, which are transparent to the client writing the data:
1. The pipeline is closed, and packets in the acknowledgement queue are added to the front of the data queue. This ensures that downstream DataNodes do not miss any packets.
2. The current block on the live DataNode is assigned a new identity. This identity is then communicated to the NameNode so that if the failed DataNode recovers later, the partial block on the failed node will be deleted.
3. The failed DataNode is removed from the pipeline, and a new pipeline is constructed from the two remaining alive DataNodes. The rest of the block’s data is written to the alive DataNodes in the pipeline.
4. The NameNode observes that the block is under-replicated and arranges for creating a further copy on another DataNode. Other incoming blocks are treated as normal.