Hadoop MapReduce
Introduction
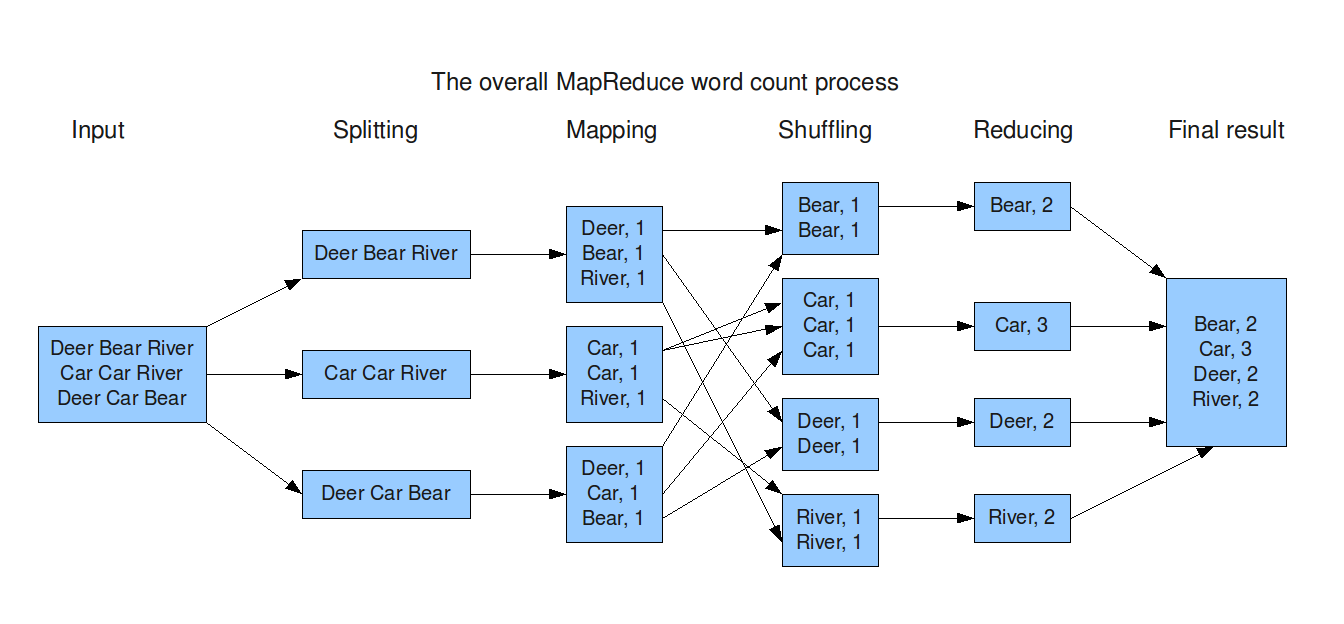
MapReduce is an algorithm or a data structure based on the YARN framework. Its main feature is to perform distributed processing in parallel in a Hadoop cluster, which makes Hadoop work much faster. When dealing with big data, serial processing is no longer effective. MapReduce has two main tasks, divided into two phases:
In the first phase, the Map function is used, and in the next phase, the Reduce function is utilized.
Here, the input is provided to the Map() function, and its output is used as input to the Reduce function. Finally, we receive our final output. Let’s understand what these Map() and Reduce() functions do.
In Big Data, the Map() function takes a set of data provided as input and breaks it into key-value pairs called Tuples. These Tuples are then sent as input to the Reduce() function. The Reduce() function combines the Tuples based on their key values, and performs operations such as sorting and summation before sending the processed data to the final output node.
The data processing in the Reducer is always determined by the business requirements of the industry. This is how Map() and Reduce() are used in sequence.
Let’s explore the Map Task and Reduce Task in detail.
Map Task
- RecordReader: The purpose of the RecordReader is to break the records. It is responsible for providing key-value pairs in the Map() function. The key is actually its locational information and the value is the data associated with it.
- Map: A map is a user-defined function that processes tuples obtained from the record reader. The Map() function either generates no key-value pairs or generates multiple pairs of these tuples.
- Combiner: The combiner is used for grouping data in the Map workflow. It is similar to a local reducer. The intermediate key-value pairs generated in the Map are combined with the help of this combiner. Using a combiner is not necessary as it is optional.
- Partitioner: The partitioner is responsible for fetching key-value pairs generated in the Mapper phase. The partitioner generates the shards corresponding to each reducer. The hashcode of each key is also fetched by this partition. Then, the partitioner performs its modulus with the number of reducers (key.hashcode() % (number of reducers)).
Reduce Task
- Shuffle and Sort: The Reducer task starts with this step, in which the intermediate key-value pairs generated by the Mapper are transferred and sorted using the process known as Shuffling. This is a faster process as it does not wait for the completion of the tasks performed by the Mapper.
- Reduce: The main function of the Reduce task is to gather the key-value pairs generated by the Mapper and perform sorting and aggregation processes on them based on their key element.
- OutputFormat: Once all the operations are completed, the key-value pairs are written to a file using a record writer, with each record on a new line and the key and value separated by a space.